Dr. Timothy Cribbin BSc (Hons), PGCert, MSc, PhD
Lecturer, Department of Computer Science
Brunel University, Uxbridge. UKE: timothydotcribbinatbruneldotacdotuk
Twitter: @timcribbin| ResearchGate | Google Scholar | Wiki CFP
ScienceDirect | ACM Digital Library | IEEExplore | ISI WOK |
Infovis Wiki | Historical IV links | VTA related links


2001-present : Lecturer, Department of Computer Science, Brunel University London
2007 : PGCert (Brunel) Learning and Teaching in Higher Education
2005 : PhD (Brunel) "Classifying complex topics using spatial-semantic document visualization: an evaluation of an interaction model to support open-ended search tasks" BURA
2000-2001 : LIC funded research assistant at DISC, Brunel University (PI: Dr Chaomei Chen)
1998-2000 : EPSRC funded research assistant at Psychology Institute, Aston University (PI: Dr Stephen Westerman)
1996 : MSc (Hull) Industrial Psychology, awarded Tom Hoyes memorial prize for dissertation (DOI)
1994 : BSc (Portsmouth) Psychology
Visual text analytics, social media analysis, citation analysis, search user interfaces, information visualisation, human-computer interaction
My work centres mainly around the field visual text analytics (VTA), where I am interested in the general problem of how to both learn plausible semantic models from unstructured or semi-structured collections of textual data and to represent/present these models in ways that support search, navigation, exploration and sense-making. Most of my work has focused on the spatial-semantic or spatialization approach. Spatialization invokes a spatial-semantic (distance-similarity) metaphor, to produce point maps or node-link graphs that summarise the general semantic relationships between documents in a corpus. Such visualisations provide the searcher or analyst with both a thematic overview of the corpus and an intuitive context in which to search and explore.
Recent projects have investigated ways to optimise the cognitive plausibility (validity) of spatial-semantic structures (Cribbin, 2010, 2011) as well as to improve the efficiency/scalability of content-based similarity computation (Cribbin, 2011). In earlier work, we explored the usability of spatializations for a variety of information seeking tasks (e.g. see Westerman and Cribbin, 2000; Cribbin and Chen, 2001; Chen et al., 2002).
I typically use a 'bag of words' vector space model approach as the basis for document similarity modelling, sometimes also using of dimension reduction (e.g. LSA). There are many ways to improve both the structural properties of both the dis(similarity) matrix and the resulting spatial layout. A particularly effect method for improving the similarity matrix is second-order similarity analysis (SOSA). SOSA transforms the first-order (i.e. term overlap) document similarity matrix to one of mutual neighbourhood (second-order) similarities. This transformation uncovers latent relationships that are not detected by first-order similarity metrics. The more near neighbours two documents share, the more likely they are to be about the same topic, which is reflected in the SOS coefficient. Recent experimental results (Cribbin, 2011) showed that SOSA can produce significantly better topic clustering than latent semantic analysis (LSA) whilst being simpler to apply because it is parameter free. A drawback of SOSA is that the run-time grows cubically with N. However, my experiments also showed that it is possible to reduce run-times significantly, without harming similarity measures, by truncating the similarity vectors prior to matrix multiplication.
Regardless of the quality of the similarity matrix, projecting these complex, high-dimensional spaces onto a 2D plane is a difficult problem. My work has focused on graph-theoretic approaches, which help to deal with the non-linearity and violation of metric assumptions associated with these spaces. I have observed good results using the Isomap method, in which the original dissimilarities are transformed to geodesic distances. These distances are estimated by computing shortest paths within a neighbourhood graph of some kind. Traditionally this might be a k-nn graph, although this presents the problem of selecting the k-parameter - too large and the graph will contain disruptive "short-circuits"; too small and the graph becomes disconnected. My work has shown that minimum-spanning trees (MST) or minimal (q=N-1) pathfinder networks tend to produce equally good spatial-semantic results without the need to tune any parameters (Cribbin, 2006, 2010).
In my PhD thesis (Cribbin, 2006), I also proposed two novel interactive interactive techniques (see image) to support visual navigation and exploration. Concept signposts are contextually relevant key words that are used to dynamically label neighbours of a selected document. The idea is that while the spatial-semantic structure tells the user which documents are neighbours, signposts explain why they are related. Concept pulses, on the other hand, allow the user to see quickly how locally salient words and phrases are distributed more globally across the document map by dynamically inflating then deflating document nodes according to their degree of match.
MST spatialization, incorporating semantic signposts and concept pulses
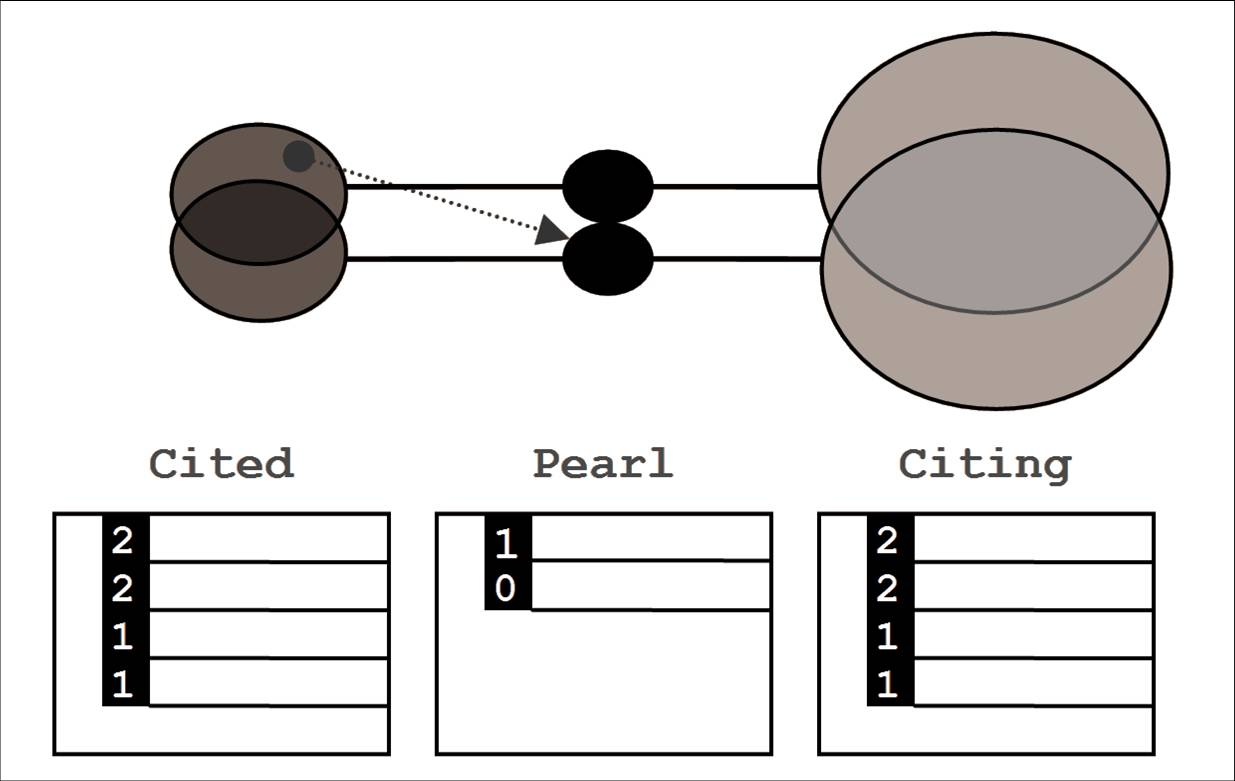
A second, current line of my research is Citation Chain Aggregation (CCA: Cribbin, 2011). CCA is an interaction model I developed to support search and analysis tasks within citation networks. Traditionally, citation chaining activity (footnote chasing and citation searching) is conducted within page-based hypertext interfaces. This results in the focus and context problem, whereby the user is attempting to gain an overview of a complex network of citations (i.e. to find relevant items and determine their relations and relative importance) but can only see a small part of that network at any one time. CCA attempts to solve this problem by simplifying the graph presentation to a three-list view, which displays the aggregation of first-order citation chains (cited<-article<-citing) surrounding a set or 'pearl' of known relevant articles (see below). As more items are added to pearl, differences in the incidence of overlap between their cited and citing articles provide a form of relevance feedback, drastically reducing the size of the search space and avoiding the need to 'navigate', node by node, through the network. See the paper and poster for a more detailed explanation of the concept. You can try CCA for yourself by downloading Oyster search here. More recently I extended the functionality of Oyster to include spatial-semantic visualisation of the pearl citation space (Cribbin, 2014). Voyster can also be downloaded from here.
CCA model
Voyster implementation of CCA
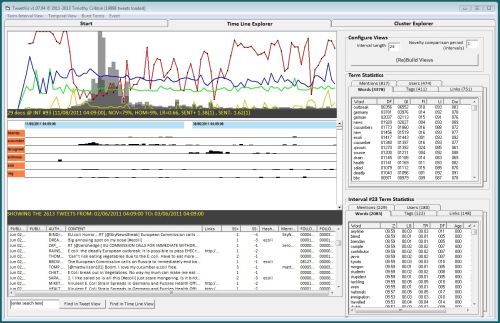
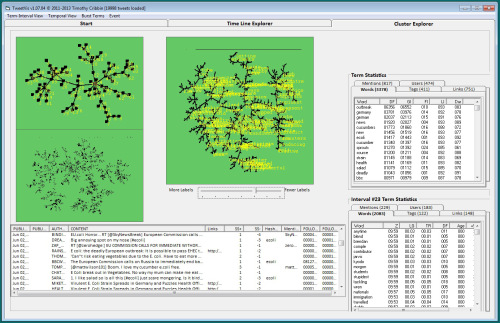
I have recently begun to explore the application potential of VTA, including sentiment analysis, as a means of supporting the analysis of social media data (e.g. Tweets, blogs, forums etc.). Our Chorus tool suite comprises the Tweetcatcher, for managing data collection and Tweetvis for analysing the retrieved datasets. So far, the focus has been within the domain of health informatics, looking for example at public perceptions and responses to health-crises such as the 2011 e-coli outbreak (see the foodRisC project) and recent/current h1n1 flu pandemics. We are also interested in the potential of social media as a source of information to support the evaluation of medical devices (see the MATCH project). A key long-term goal here is to develop tools for social (and mainstream) media analysis that enable social scientists to readily leverage the powerful methods developed by the text mining and information visualization communities within the last two decades. Progress can be followed on the Chorus site and a video introduction can be found here.
Chorus Timeline Explorer Chorus Cluster Explorer I currently belong to the Centre for Intelligent Data Analysis (CIDA) within the Department of Computer Science. I was previously a co-investigator on the MATCH project. If you are interested in reading for a PhD in any of the topic areas mentioned above, please email me using the address at the top of the page.
Click here to see lists of the top 10 most cited books, journal and conference papers in IV (based on data to 2009).

{kind=link}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|